
- Features
- Searchable Fields
- Libraries
- Facet Features
- Types of Facets
- Configure Facets
- Field Mapping
- Field Properties
- Configure Site
- Profile
- Team Management
- Sites
- Global Coverage
- Disaster Recovery
- Features
- Template Selection
- Keyword Suggestions
- In-Field Suggestions
- Top Search Queries
- Popular Products
- Trending Queries
- Promoted/Blacklisted Suggestions
- Real-time Preview
- Instantaneous Publishing
- Ranking Insights
- Clickstream Data
- Boost/Bury
- Sort
- Slot
- Pin
- Filter
- Landing Pages
- Redirects
- Set Banners
- Ranking Insights
- Create a Site Rule
- Managing Field Rules
- Managing Query Rules
- Campaign
- A top-down approach
- Faster and simpler
- Relevant Metrics for better analysis
- Interactive and easy-to-view preview
- Feature-filled Listing Page
- Promotions
- Banners
- Facets
- Redirects
- Add New Promotions
- Boost/Bury
- Sort
- Slot
- Pin
- Filter
- Landing Pages
- All Queries
- Query-based Banner
- Field-based Banner
- Creating Field-based Facets
- Create a Site Rule
- Overall Performance
- Query Report
- Zero Result Queries
- Product Reports
- In-field Suggestions
- Keyword Suggestions
- Top Search Queries
- Popular Products
Unbxd products are deployed using a distributed architecture with clusters available on all major continents. The performance of our products is further accelerated by Cloudflare’s content delivery network coverage which also comes with advanced security measures including DDoS protection. The response time is a critical factor influencing shopper’s experience on your website and we are committed to offering the best performance in addition to highly relevant search results.
Unbxd infrastructure is hosted on Amazon Web Services (AWS) in the following regions :
- United States (US)
- United Kingdom (UK)
- Singapore (SG)
- Australia and New Zealand (ANZ)

Scalability
We understand that the traffic on your website varies with time so the infrastructure supporting the product discovery should be elastic enough to accommodate a surge in demand. We have built many options in our services to offer scalability
- Spare capacity maintained during normal operations: Our services are configured with extra capacity to accommodate any sudden surge in traffic.
- Auto-scaling Microservices: Our cloud infrastructure scales automatically in accordance with the resource requirements to offer a stable performance irrespective of the traffic volume. The autoscaling is achieved by using Kubernetes for all micro-services that enables horizontal scaling of services depending upon the demand.
- Caching: Unbxd maintains an extensive cache capable of serving requests. During peak loads, the cache is used to serve some requests in order to reduce the load on downstream services and allow the autoscaling of services.
- Monitoring & Proactive actions: In addition to these, our platform stability team has built an extensive monitoring capability to measure system performance and take proactive action.
Redundancy & Data backup
Our architecture is designed to provide enterprise-grade reliability and eliminate single points of failure.
- Redundancy maintained across multiple availability zones: Within a cluster ( AWS region) all the micro-services are distributed across multiple AWS availability zones to avoid service disruption due to ones happening in a single availability zone (physical data center location).
- Automated recovery: All microservices in our system are designed to automatically recover from unexpected failures with the help of a monitoring system that identifies & isolates the unresponsive nodes/servers. Services are maintained at low utilization levels under normal operations to reduce the impact on performance & availability when the load is re-distributed.
- Multiple index replicas: We also ensure redundancy at the index level by maintaining multiple replicas of the search index along with some failover index replicas which are utilized when the primary index is unavailable.
- Data backup: Data uploaded on our platform (including catalog data, merchandising rules) is stored in data centers distributed across multiple regions to achieve redundancy.
Request Lifecycle
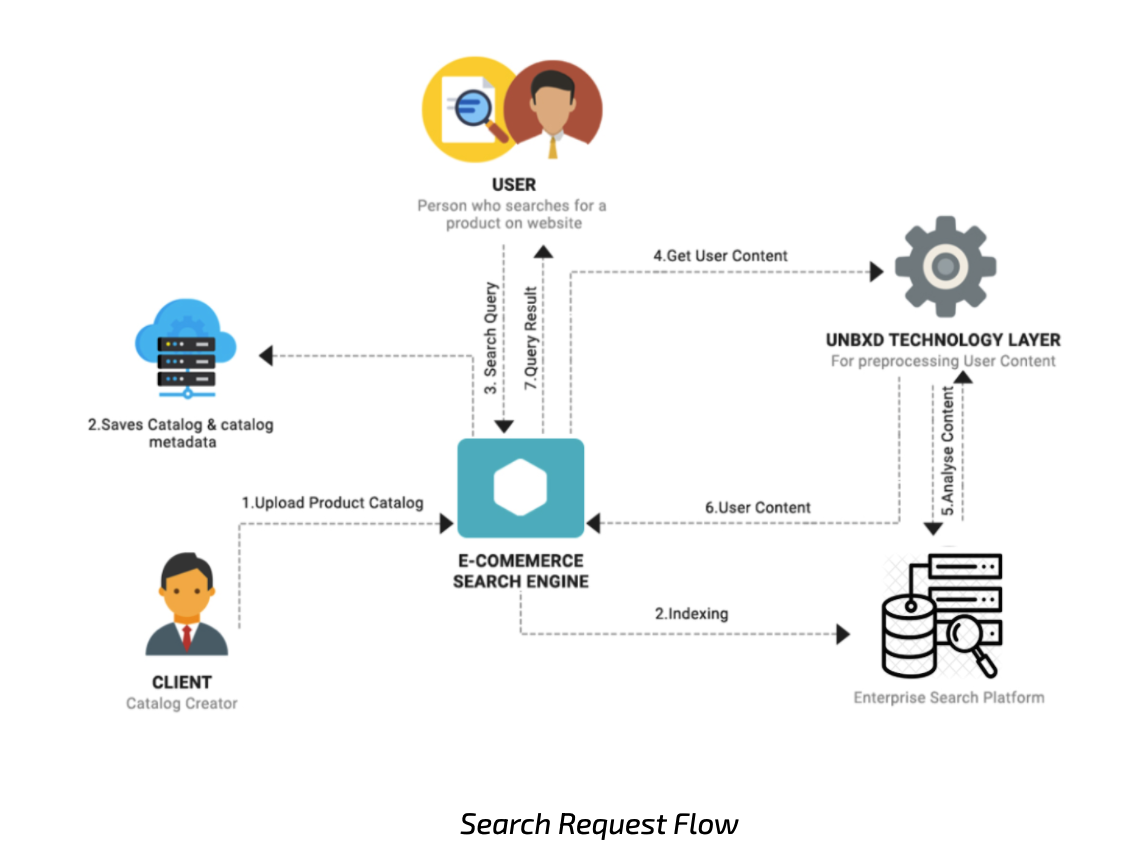
The figure above is a simplified representation of the feed/catalog upload & search request lifecycle.
- Feed upload request: The steps 1 & 2 above represent the feed/catalog upload request lifecycle. Our feed indexing process is highly scalable and allows customers the flexibility to upload the entire catalog in a single request (full feed upload) or perform incremental catalog uploads to update the records that have changed (delta feed upload). A secret key is for authentication of all feed upload requests. The feed indexing process is isolated from the request serving infrastructure to avoid disruption in services during indexing.
- Search/Category request: Steps 3, 4, 5, 6, and 7 in the figure above represent the sequence of steps required to generate the result set for a search/browse (category) and autosuggest request.
The search request received from the shopper is processed by our proprietary technology layer for processing a query to detect the shopper’s intent, apply business rules, and perform query expansion. The technology layer then communicates with the Index to retrieve products & rank them in order to optimize conversions.
Our architecture is robust and resilient by design and can handle a wide range of traffic and catalog sizes. However, there are certain factors which are outside our control that can impact the availability of services. Downtimes, especially during the peak sale times, can be costly for your business as it may lead to loss of potential revenue. For instance, Costco lost $11 Mn in sales due to downtime in 2019, effectively losing ~$11,000 in revenue every minute due to the incident.
The disaster recovery solution offers a mechanism to resume operations in an alternate data center (present in a different geographical location) if the primary data center becomes unavailable. The disaster recovery solution offers a quick failover mechanism to fallback to a secondary data center if the primary data center becomes unavailable.
How does the DR solution offer higher availability?
The DR solution mitigates the risk of a wide-scale outage due to the unavailability of CDN service providers or cloud infrastructure providers (data center). The DR solution has the following systems in place to mitigate these risks :
- Option to bypass CDN: The DR solution offers an option to directly communicate with Unbxd clusters by bypassing the CDN.
- Circuit break & Caching layer: Circuit breaker detects unavailability of downstream services and routes the request to the failover cluster or allows our system to use cached data to provide a response to incoming requests. Unbxd maintains 2 layers of cache to minimize disruption of services while traffic is routed to the failover cluster.
- Failover to DR cluster: All data from the primary cluster is replicated to a secondary cluster at regular intervals. The secondary cluster acts as a standby cluster capable of handling live traffic when the primary cluster is unavailable.
Salient Features of the DR solution
- Quickly scale-up the DR cluster: DR solution is built using the Spotinst platform to scale up services within minutes. A few stateless services will be autoscaled to maintain latency & SLA.
- Fully managed by Unbxd: Unbxd manages the data replication and failover to the DR solution. The traffic will be automatically switched to the failover/DR cluster when the primary cluster is unavailable. No intervention needed from the customers’ end.
- New Endpoints: The DR solution offers new endpoints for bypassing Cloudflare or directly hitting the DR cluster. These endpoints can be used by customers for testing the DR offering or routing production traffic to the DR solution.
SLA
- Recovery point objective (RPO) : The RPO for DR solution is 2 hours. RPO represents the maximum time to backup.
- Recovery time objective (RTO) : The RTP for DR solution is automated by Unbxd.
Instructions & DR Endpoint
The replication lag in the DR cluster can be up to 2 hours which means the feed data & merchandising rules may not be the most recent data. Hence, the DR end-point must only be used when the primary end-point is not available.
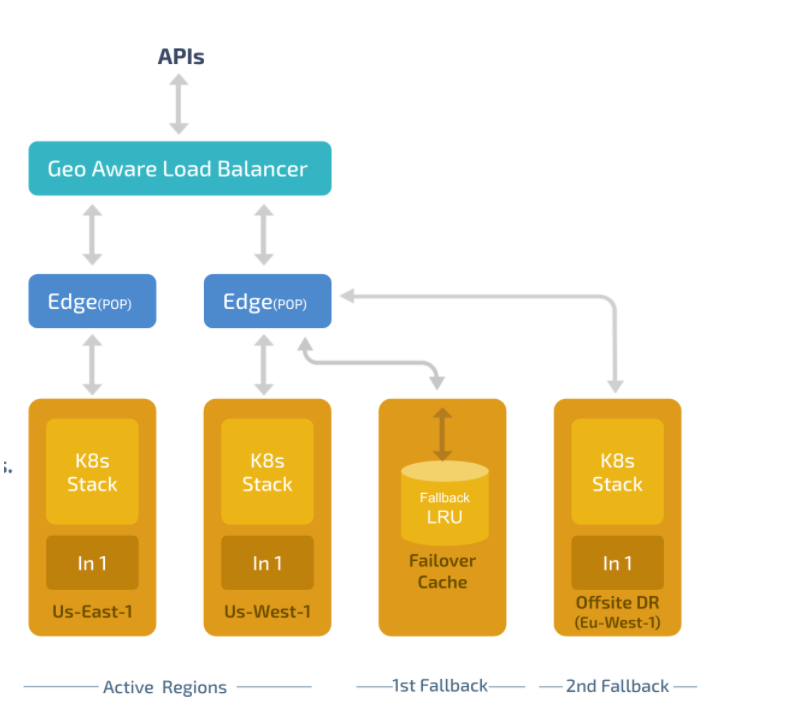
Automated DR Routing
Unbxd systems are designed to automatically detect failures in the primary search cluster and route the requests to the DR cluster. A circuit breaker is placed in the request flow to detect failures in the primary search cluster and automatically routes the request to a failover mechanism that servers the request from cache (if available) or DR cluster.
- Did this answer your question?

