- ProductsSearch and BrowseRecommendationsCustomer Engagement
Why shoppers struggle to find products, and how multimodal search fixes it




Why is multimodal search becoming essential in ecommerce?
A shopper sees a stunning armchair in a friend’s home.
They love it. They want it.
So they open your ecommerce site and type… what exactly?
“Mid-century modern chair with curved arms and mustard yellow fabric?”
“Retro lounge chair vintage style?”
“Round armchair yellow?”
None of these searches surface the right product, even if you sell it.
This isn’t a shopper problem. It’s a discovery problem. And it quietly costs retailers sales every single day.
Increasingly, the answer isn’t better keywords or more filters.
It’s multimodal search.
What is multimodal search?
Multimodal search is a search experience that understands more than one type of input at the same time, typically image and text, and interprets them within a shared semantic framework. Instead of forcing shoppers to translate a visual memory into keywords, it allows them to upload a photo and refine it with natural language.
That combination matters more than most retailers realize.
Key Takeaways
-
People remember shape, color, texture, and overall aesthetic. Traditional keyword search forces them to translate that visual memory into structured terms, and that translation often fails.
-
Inconsistent tagging, missing style attributes, and subjective terminology create discovery gaps, even when the right product exists in the catalog.
-
It answers “What looks like this?” but struggles with layered intent such as budget constraints, material preferences, or occasion-specific needs.
-
Modern shoppers combine inspiration with constraints. They want products that look like this, but cheaper, different color, premium material, or work-appropriate. Multimodal search enables that natural refinement.
-
By processing image and text together in a shared semantic framework, multimodal search moves beyond surface resemblance toward contextual relevance.
-
Building on strong AI ranking, personalization, and visual search foundations, Netcore Unbxd integrates text and image into a single commerce-aware intent engine.
Why do shoppers struggle to describe what they want?
The gap between visual memory and verbal description is wider than it appears.
When people see a product they like, their brain doesn’t store it as keywords. They remember shape, color, texture, proportions, and overall feel. They remember aesthetics, not attributes.
Traditional ecommerce search forces shoppers to translate that visual memory into precise terminology. That translation often breaks down.
Is the style “bohemian” or “eclectic”?
Is the pattern “geometric” or “abstract”?
Is the look “minimalist” or “Scandinavian”?
Your catalog might use one term. The shopper guesses another. The search fails.
This problem compounds in visually driven categories like fashion, furniture, jewelry, and home décor, where discovery matters most and language is least precise.
The current state: Why does keyword search fail even when intent is high?
Even highly motivated shoppers can’t overcome imperfect product data.
Most ecommerce catalogs contain:
- Missing or shallow style attributes
- Inconsistent color naming like “burgundy” vs “wine” vs “deep red”
- Generic descriptions that ignore visual nuance
- Supplier-provided tags that were never normalized
A shopper searching for a “floral midi dress” may miss the perfect product simply because it’s tagged as “garden print mid-length dress” or lacks style metadata altogether.
Keyword search can only match what’s explicitly written. If visual meaning isn’t encoded in text, the search engine stays blind to it.
Visual search helps, but it’s only part of the answer
Visual search emerged to address this gap. Instead of asking shoppers to describe what they want, it lets them show it.
Uploading an image allows systems to identify similarities in:
- Shape and silhouette
- Color and pattern
- Overall aesthetic
For inspiration-led shopping, this is a meaningful improvement over text-only search.
But visual search alone has limits.
Image-only systems are very good at answering:
“What looks like this?”
They struggle to answer:
“What looks like this, but matches what I actually want?”
That difference is where discovery often breaks down.
How shoppers actually search today
Mobile cameras have fundamentally changed search behavior.
Shoppers increasingly expect to:
- Screenshot inspiration from Instagram, Pinterest, or blogs
- Snap photos of products they see in stores or real-world settings
- Upload images directly instead of typing long descriptions
This behavior is already mainstream.
Yet many ecommerce experiences still treat search as a binary choice: text or image. That’s not how people think.
Real shopping intent is rarely visual-only or text-only. It’s a combination.
Where visual search alone breaks down
Pure visual similarity struggles when shoppers need control or refinement.
Common scenarios include:
- “I like this, but it’s too expensive”
- “Same design, different material”
- “This vibe, but more colorful”
- “Something like this, but suitable for work”
An image can anchor style, but it can’t express constraints like price, material, occasion, or preference shifts on its own.
This is where multimodal search becomes essential.
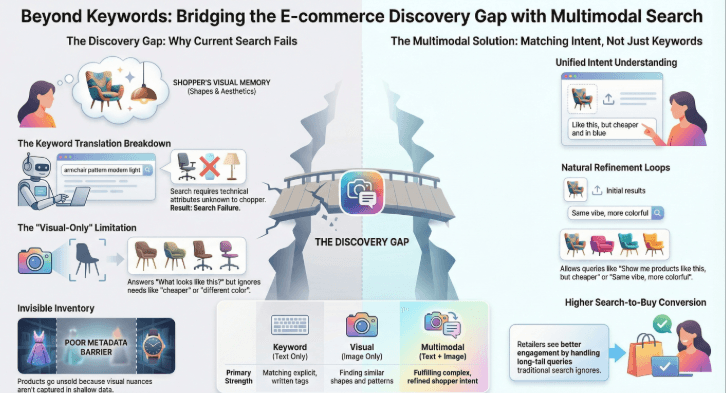
What does multimodal search mean at Netcore Unbxd?
Multimodal search at Netcore Unbxd allows shoppers to combine images and text in a single search experience, instead of forcing a choice between them.
The system understands:
- Visual signals from images, including style, silhouette, pattern, and design language
- Textual intent from queries like color preference, price sensitivity, material, or occasion
Both inputs are interpreted together to form a unified understanding of shopper intent.
For example, when a shopper uploads an image of a dress and adds “but in blue,” Netcore Unbxd’s multimodal search:
- Understands the visual style and cut from the image
- Interprets the color requirement from text
- Surfaces products that preserve the aesthetic while meeting the constraint
Search moves from similarity matching to intent fulfillment.
How multimodal search mirrors real shopper thinking
Multimodal queries reflect how people naturally refine decisions.
Examples include:
“Show me products like this, but cheaper”
The image anchors style. Text introduces price sensitivity.
“Similar design, different material”
Visual similarity drives discovery. Language defines the variation.
“Same vibe, more colorful”
The aesthetic comes from the image. Words shape the outcome.
Visual search answers what looks similar.
Multimodal search answers what looks right.
That distinction determines whether discovery ends in browsing or buying.
What problems Netcore Unbxd’s multimodal search solves
By combining visual understanding with language-based refinement, Netcore Unbxd addresses challenges that traditional search struggles with:
- Vocabulary gaps, when shoppers don’t know technical terms
- Inspiration-led journeys, where shoppers want an aesthetic, not an exact SKU
- Incomplete metadata, by relying on visual intelligence when tags fall short
- Vague or ambiguous queries, where text alone provides too little signal
The result is a more resilient discovery, even when shopper input is imperfect.
Why retailers are adopting multimodal search now
Three forces are converging:
Mobile-first behavior
Cameras are faster than typing, especially on small screens.
Visual competition
In saturated categories, products win on aesthetics, not specifications.
Rising AI expectations
Shoppers expect systems to understand intent without perfect input.
Search experiences that demand precise keywords increasingly feel outdated.
How multimodal search impacts business outcomes
The value of multimodal search extends beyond novelty.
Retailers typically see:
- Higher engagement on search results pages
- Better performance on inspiration-led journeys
- Improved handling of long-tail and poorly phrased queries
- Stronger differentiation in visually competitive categories
The gains are most pronounced where traditional keyword search underperforms most.
What to consider before implementing multimodal search?
Multimodal search works best when:
- Product imagery is high quality and consistent
- Visual differentiation influences purchase decisions
- There is a genuine discovery problem to solve
- The experience supports refinement, not just image upload
It isn’t a replacement for good data or UX, but a powerful layer on top of both.
Visual search helps shoppers find things that look similar.
Multimodal search helps them find what they actually want.
As ecommerce shifts from lookup to discovery, the ability to understand both what shoppers see and what they mean becomes the difference between search that works and search that converts.
From advanced visual search to unified multimodal intelligence
Even before multimodal search, Netcore Unbxd was recognized for its strong AI-powered product discovery, including robust visual search capabilities.
The platform already enabled shoppers to upload an image and discover visually similar products. Alongside this, it delivered:
- AI-driven keyword ranking optimized by behavioral signals
- Real-time personalization at query level
- Merchandising controls for business alignment
- Conversion-aware relevance tuning
In structured text environments, it performed exceptionally well. In image-led journeys, visual similarity helped power inspiration-driven discovery. Search was already intelligent, commerce-aware, and optimized for revenue impact.
However, text search and visual search largely operated as parallel capabilities.
Multimodal search represents the next architectural step.
Instead of treating text and image as separate experiences, the system now interprets them together within a shared semantic space. A shopper can combine visual intent with textual refinement in a single interaction.
This evolution introduces three key improvements:
1. From separate modalities to unified intent
Earlier:
- Text queries powered keyword ranking
- Image uploads powered visual similarity
Now:
- Image and text signals are processed simultaneously
- The system understands what the shopper means across both inputs
2. From similarity matching to contextual refinement
Visual search previously focused on “find products that look like this.”
Multimodal search enables “find products that look like this, but cheaper,” or “same design, different material.”
Intent becomes layered, not singular.
3. From capability feature to discovery architecture
Visual search was a powerful feature.
Multimodal search transforms it into a structural layer that strengthens:
- AI ranking
- Personalization models
- Merchandising strategies
- Long-tail recall
- Search rescue for weak queries
The improvement is not about adding image understanding. It is about unifying all shopper signals into a single, commerce-aware intent engine.
Learn more about Netcore Unbxd Multimodal search.
FAQs
1. What is multimodal search in ecommerce?
Multimodal search is a search experience that combines image input and text input in a single query. Instead of choosing between uploading a photo or typing a description, shoppers can do both. The image anchors visual intent, while text refines it with constraints like color, price, material, or occasion.
2. How is multimodal search different from visual search?
Visual search answers the question, “What looks like this?” by identifying visually similar products.
Multimodal search answers, “What looks like this, but fits my specific needs?” It interprets visual similarity and textual refinement together, allowing shoppers to modify style, budget, color, or use case in the same search.
3. Why does traditional keyword search fail in visually driven categories?
Keyword search depends entirely on product metadata. If style attributes are missing, inconsistent, or poorly tagged, relevant products may never appear.
In categories like fashion, furniture, jewelry, and home décor, shoppers often think in terms of aesthetics rather than technical attributes. That gap between visual memory and catalog terminology leads to missed matches.
4. When should a retailer consider implementing multimodal search?
Multimodal search is most effective when:
- Visual differentiation influences buying decisions
- Shoppers frequently browse for inspiration
- Product imagery is high quality and consistent
- Discovery challenges impact conversions
If shoppers struggle to find products even when inventory exists, multimodal search can significantly improve discovery.
5. How does multimodal search impact business metrics?
Retailers adopting multimodal search often see:
- Increased engagement on search results pages
- Higher conversion rates on inspiration-led journeys
- Improved performance on long-tail or ambiguous queries
- Better handling of imperfect or incomplete shopper input





